1.5 GRPO — RLVR 的奠基算法¶
本节摘要
GRPO 消除了 Critic 网络和奖励模型,通过组内相对奖励估计优势函数,奠定了 RLVR 范式的技术基础。本节包含完整公式推导及局限性分析。
论文:GRPO
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (Shao et al., 2024) arXiv: 2402.03300 地位: Value-Free RL 路线的开创者,RLVR 范式的确立,DeepSeek-R1 的核心算法
核心思想¶
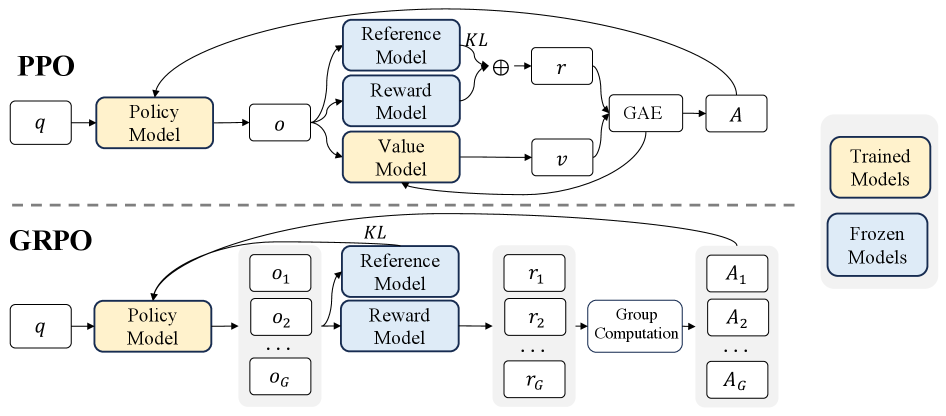
GRPO 的核心洞察:不需要价值网络(Critic),也不需要训练奖励模型。对同一个问题采样一组(Group)回答,用组内的相对奖励来估计优势,用规则判定(答案是否正确)来提供奖励。
GRPO = Value-Free + RM-Free,这正是 RLVR 范式得以成立的技术基础。
核心公式¶
GRPO 目标函数:
与 PPO 的关键区别——优势函数的计算方式:
其中 \(\mathbf{R} = \{R_1, R_2, \ldots, R_G\}\) 是同一问题下 \(G\) 个采样回答的奖励集合。在 RLVR 范式下,\(R_i \in \{+1, -1\}\)(答案对/错)。
📖 初学者补充:Group Relative 是什么意思?
举个例子:对问题 "求 \(\sqrt{144}\)",模型生成 8 个回答(Group Size \(G=8\)):
| 回答 | 正确? | 奖励 \(R_i\) |
|---|---|---|
| \(o_1\): "12" | ✅ | +1 |
| \(o_2\): "14" | ❌ | -1 |
| \(o_3\): "12" | ✅ | +1 |
| \(o_4\): "11" | ❌ | -1 |
| ... | ... | ... |
计算:\(\text{mean}(\mathbf{R}) = 0\),\(\text{std}(\mathbf{R}) = 1\)
- 正确回答:\(\hat{A} = (1 - 0)/1 = +1\)(鼓励)
- 错误回答:\(\hat{A} = (-1 - 0)/1 = -1\)(抑制)
这就是 "Group Relative":优势是相对于同组其他回答的,不需要 Critic 网络来估计。
GRPO 的 KL 散度估计器(无偏估计):
为什么这么设计¶
| 设计决策 | 动机 | 解决的问题 |
|---|---|---|
| 消除 Critic 网络 | Critic 在 LLM 稀疏奖励场景下训练困难 | 4 模型 → 3 模型,节省 ~25% 显存 |
| 消除 RM | 数学/代码任务有确定答案,不需要学习的奖励模型 | 杜绝 Reward Hacking |
| 组内相对奖励 | 对/错的二元奖励天然适合相对比较 | 无需绝对准确的价值估计 |
| 保留 PPO 裁剪 | 裁剪仍然是稳定训练的有效手段 | 防止策略突变 |
GRPO 的局限¶
- Hard Clipping 丢失梯度: 被裁剪的 token 梯度变为 0,某些稀有但重要的推理词(如 "however", "wait")可能永远学不到
- Token-Level IS 高方差: 逐 token 的重要性采样权重在长序列中波动剧烈
- 长序列中 Group Baseline 精度不足: 同一组所有 token 共享同一个优势值,无法区分序列内部不同位置的贡献
📖 深入理解:为什么 Hard Clipping 会让被裁剪 token 的梯度变为 0?
PPO/GRPO 的目标函数对单个 token 的贡献:
当 \(\hat{A}_t > 0\)(好 token)且 \(r_t > 1 + \varepsilon\) 时(新策略已经大幅增加了这个 token 的概率),\(\min\) 取常数项 \((1+\varepsilon) \cdot \hat{A}_t\),这是关于 \(\theta\) 的常数,所以 \(\nabla_\theta L_t = 0\)。
PPO 的裁剪等价于一个二值掩码:
对稀有推理词的影响:像 "However" 这样的词在基座模型中概率可能只有 \(\pi_{\text{old}} = 0.005\)。模型概率增长到 \(0.01\) 时,\(r_t = 2.0\),远超 \(1.2\),梯度归零——尽管绝对概率只有 1%,离"学会"还差很远。